Note
This tutorial was generated from an IPython notebook that can be downloaded here.
Model fitting with correlated noise#
This notebook was made with the following version of george:
import george
george.__version__
'0.3.1'
In this example, we’re going to simulate a common data analysis situation where our dataset exhibits unknown correlations in the noise. When taking data, it is often possible to estimate the independent measurement uncertainty on a single point (due to, for example, Poisson counting statistics) but there are often residual systematics that correlate data points. The effect of this correlated noise can often be hard to estimate but ignoring it can introduce substantial biases into your inferences. In the following sections, we will consider a synthetic dataset with correlated noise and a simple non-linear model. We will start by fitting the model assuming that the noise is uncorrelated and then improve on this model by modeling the covariance structure in the data using a Gaussian process.
A Simple Mean Model#
The model that we’ll fit in this demo is a single Gaussian feature with three parameters: amplitude \(\alpha\), location \(\ell\), and width \(\sigma^2\). I’ve chosen this model because is is the simplest non-linear model that I could think of, and it is qualitatively similar to a few problems in astronomy (fitting spectral features, measuring transit times, etc.).
Simulated Dataset#
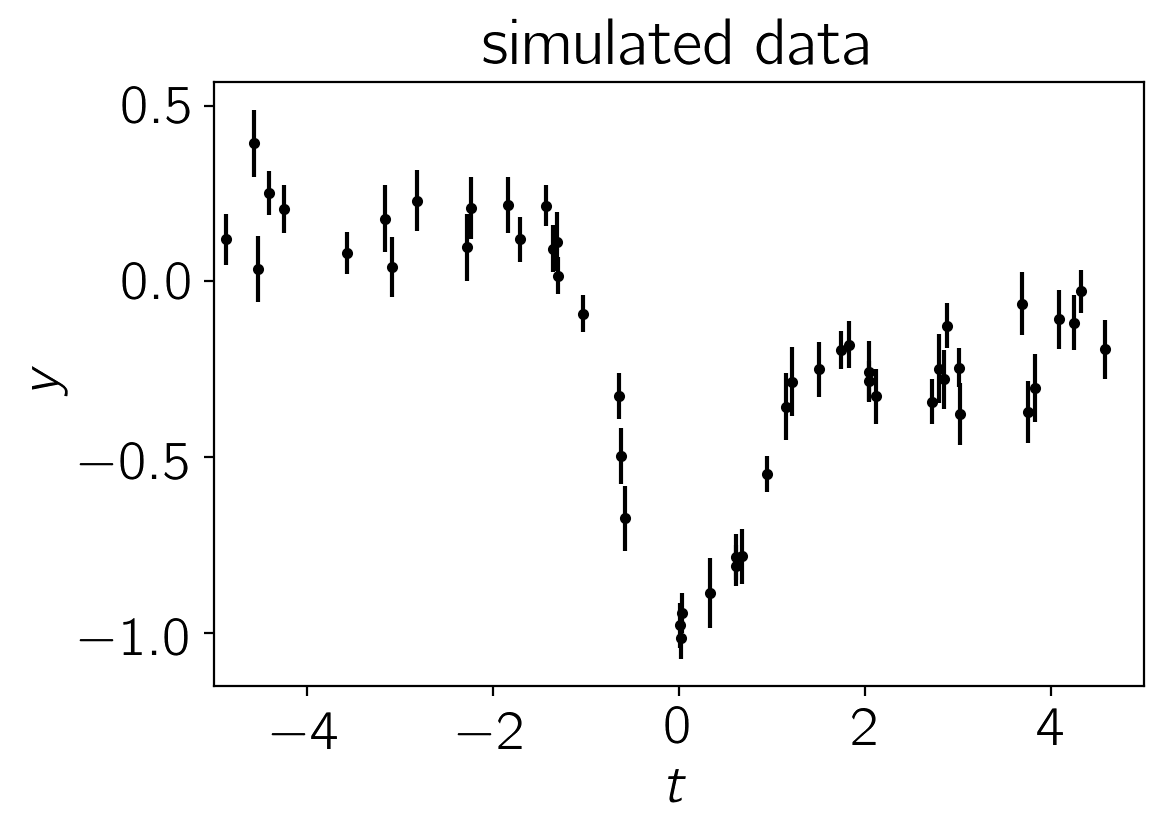
Let’s start by simulating a dataset of 50 points with known correlated noise. In fact, this example is somewhat artificial since the data were drawn from a Gaussian process but in everything that follows, we’ll use a different kernel function for our inferences in an attempt to make the situation slightly more realistic. A known white variance was also added to each data point.
Using the parameters
the resulting dataset is:
from george.modeling import Model
class Model(Model):
parameter_names = ("amp", "location", "log_sigma2")
def get_value(self, t):
return self.amp * np.exp(-0.5*(t.flatten()-self.location)**2 * np.exp(-self.log_sigma2))
import numpy as np
import matplotlib.pyplot as pl
from george import kernels
np.random.seed(1234)
def generate_data(params, N, rng=(-5, 5)):
gp = george.GP(0.1 * kernels.ExpSquaredKernel(3.3))
t = rng[0] + np.diff(rng) * np.sort(np.random.rand(N))
y = gp.sample(t)
y += Model(**params).get_value(t)
yerr = 0.05 + 0.05 * np.random.rand(N)
y += yerr * np.random.randn(N)
return t, y, yerr
truth = dict(amp=-1.0, location=0.1, log_sigma2=np.log(0.4))
t, y, yerr = generate_data(truth, 50)
pl.errorbar(t, y, yerr=yerr, fmt=".k", capsize=0)
pl.ylabel(r"$y$")
pl.xlabel(r"$t$")
pl.xlim(-5, 5)
pl.title("simulated data");
Assuming White Noise#
Let’s start by doing the standard thing and assuming that the noise is uncorrelated. In this case, the ln-likelihood function of the data \(\{y_n\}\) given the parameters \(\theta\) is
where \(A\) doesn’t depend on \(\theta\) so it is irrelevant for our purposes and \(f_\theta(t)\) is our model function.
It is clear that there is some sort of systematic trend in the data and we don’t want to ignore that so we’ll simultaneously model a linear trend and the Gaussian feature described in the previous section. Therefore, our model is
where \(\theta\) is the 5-dimensional parameter vector
The following code snippet is a simple implementation of this model in Python.
class PolynomialModel(Model):
parameter_names = ("m", "b", "amp", "location", "log_sigma2")
def get_value(self, t):
t = t.flatten()
return (t * self.m + self.b +
self.amp * np.exp(-0.5*(t-self.location)**2*np.exp(-self.log_sigma2)))
To fit this model using MCMC (using emcee), we need to first choose priors—in this case we’ll just use a simple uniform prior on each parameter—and then combine these with our likelihood function to compute the ln-probability (up to a normalization constant). In code, this will be:
model = george.GP(mean=PolynomialModel(m=0, b=0, amp=-1, location=0.1, log_sigma2=np.log(0.4)))
model.compute(t, yerr)
def lnprob(p):
model.set_parameter_vector(p)
return model.log_likelihood(y, quiet=True) + model.log_prior()
Now that we have our model implemented, we’ll initialize the walkers and run both a burn-in and production chain:
import emcee
initial = model.get_parameter_vector()
ndim, nwalkers = len(initial), 32
p0 = initial + 1e-8 * np.random.randn(nwalkers, ndim)
sampler = emcee.EnsembleSampler(nwalkers, ndim, lnprob)
print("Running burn-in...")
p0, _, _ = sampler.run_mcmc(p0, 500)
sampler.reset()
print("Running production...")
sampler.run_mcmc(p0, 1000);
Running burn-in...
Running production...
After running the chain, we can plot the predicted results. It is often useful to plot the results on top of the data as well. To do this, we can over plot 24 posterior samples on top of the data:
# Plot the data.
pl.errorbar(t, y, yerr=yerr, fmt=".k", capsize=0)
# The positions where the prediction should be computed.
x = np.linspace(-5, 5, 500)
# Plot 24 posterior samples.
samples = sampler.flatchain
for s in samples[np.random.randint(len(samples), size=24)]:
model.set_parameter_vector(s)
pl.plot(x, model.mean.get_value(x), color="#4682b4", alpha=0.3)
pl.ylabel(r"$y$")
pl.xlabel(r"$t$")
pl.xlim(-5, 5)
pl.title("fit assuming uncorrelated noise");
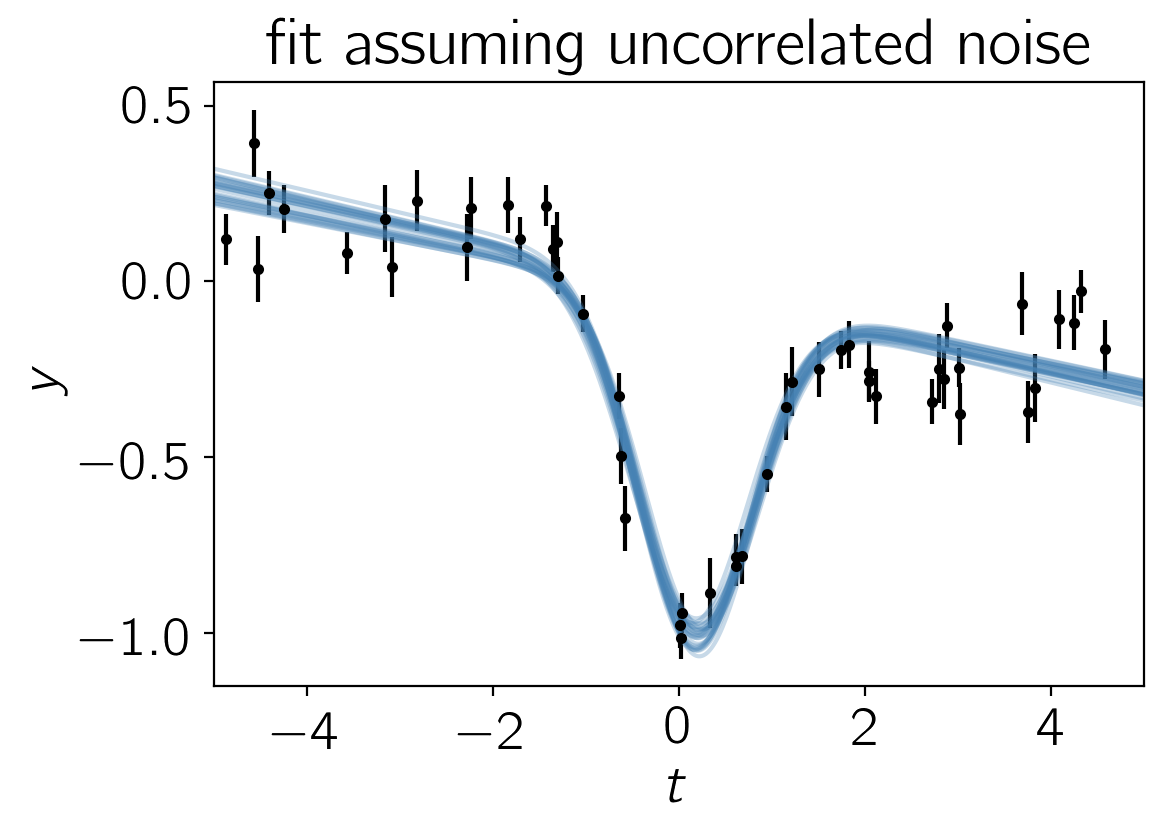
In this figure, the data are shown as black points with error bars and the posterior samples are shown as translucent blue lines. These results seem, at face value, pretty satisfying. But, since we know the true model parameters that were used to simulate the data, we can assess our original assumption of uncorrelated noise. To do this, we’ll plot all the projections of our posterior samples using corner.py and over plot the true values:
import corner
tri_cols = ["amp", "location", "log_sigma2"]
tri_labels = [r"$\alpha$", r"$\ell$", r"$\ln\sigma^2$"]
tri_truths = [truth[k] for k in tri_cols]
tri_range = [(-2, -0.01), (-3, -0.5), (-1, 1)]
names = model.get_parameter_names()
inds = np.array([names.index("mean:"+k) for k in tri_cols])
corner.corner(sampler.flatchain[:, inds], truths=tri_truths, labels=tri_labels);
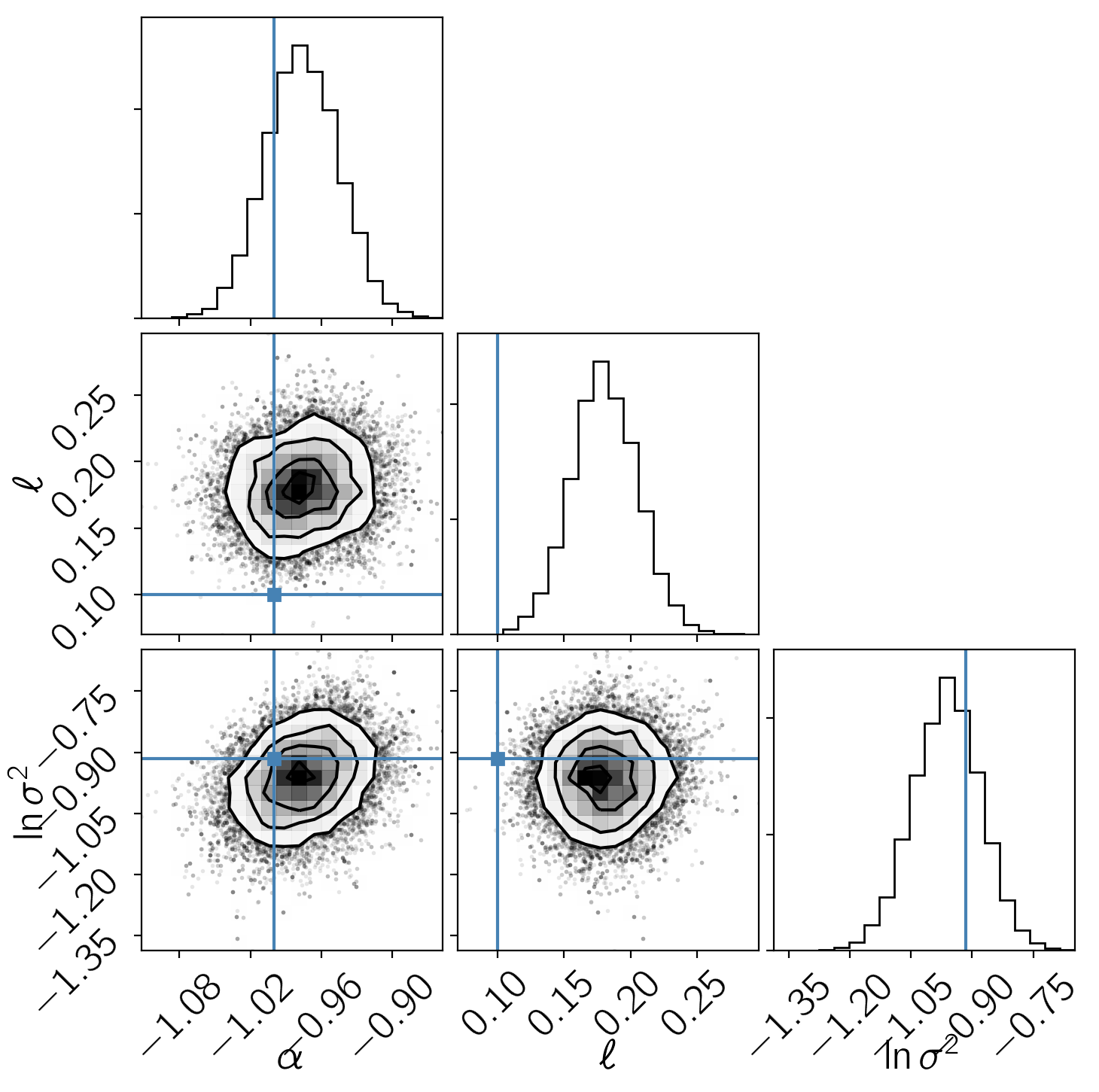
In this figure, the blue lines are the true values used to simulate the data and the black contours and histograms show the posterior constraints. The constraints on the amplitude \(\alpha\) and the width \(\sigma^2\) are consistent with the truth but the location of the feature \(\ell\) is almost completely inconsistent with the truth! This would matter a lot if we were trying to precisely measure radial velocities or transit times.
Modeling the Noise#
Note: A full discussion of the theory of Gaussian processes is beyond the scope of this demo—you should probably check out Rasmussen & Williams (2006)—but I’ll try to give a quick qualitative motivation for our model.
In this section, instead of assuming that the noise is white, we’ll generalize the likelihood function to include covariances between data points. To do this, let’s start by re-writing the likelihood function from the previous section as a matrix equation (if you squint, you’ll be able to work out that we haven’t changed it at all):
where
is the residual vector and
is the \(N \times N\) data covariance matrix (where :math:N is
the number of data points).
The fact that \(K\) is diagonal is the result of our earlier assumption that the noise was white. If we want to relax this assumption, we just need to start populating the off-diagonal elements of this covariance matrix. If we wanted to make every off-diagonal element of the matrix a free parameter, there would be too many parameters to actually do any inference. Instead, we can simply model the elements of this array as
where \(\delta_{ij}\) is the Kronecker_delta and \(k(\cdot,\,\cdot)\) is a covariance function that we get to choose. Chapter 4 of Rasmussen & Williams discusses various choices for \(k\) but for this demo, we’ll just use the Matérn-3/2 function:
where \(r = |t_i - t_j|\), and \(a^2\) and \(\tau\) are the parameters of the model.
The Final Fit#
Now we could go ahead and implement the ln-likelihood function that we came up with in the previous section but that’s what George is for, after all! To implement the model from the previous section using George, we can write the following ln-likelihood function in Python:
kwargs = dict(**truth)
kwargs["bounds"] = dict(location=(-2, 2))
mean_model = Model(**kwargs)
gp = george.GP(np.var(y) * kernels.Matern32Kernel(10.0), mean=mean_model)
gp.compute(t, yerr)
def lnprob2(p):
gp.set_parameter_vector(p)
return gp.log_likelihood(y, quiet=True) + gp.log_prior()
As before, let’s run MCMC on this model:
initial = gp.get_parameter_vector()
ndim, nwalkers = len(initial), 32
sampler = emcee.EnsembleSampler(nwalkers, ndim, lnprob2)
print("Running first burn-in...")
p0 = initial + 1e-8 * np.random.randn(nwalkers, ndim)
p0, lp, _ = sampler.run_mcmc(p0, 2000)
print("Running second burn-in...")
p0 = p0[np.argmax(lp)] + 1e-8 * np.random.randn(nwalkers, ndim)
sampler.reset()
p0, _, _ = sampler.run_mcmc(p0, 2000)
sampler.reset()
print("Running production...")
sampler.run_mcmc(p0, 2000);
Running first burn-in...
Running second burn-in...
Running production...
You’ll notice that this time I’ve run two burn-in phases. Before the second burn-in, I re-sample the positions of the walkers in a tiny ball around the position of the best walker in the previous run. I found that this re-sampling step was useful because otherwise some of the walkers started in a bad part of parameter space and took a while to converge to something reasonable.
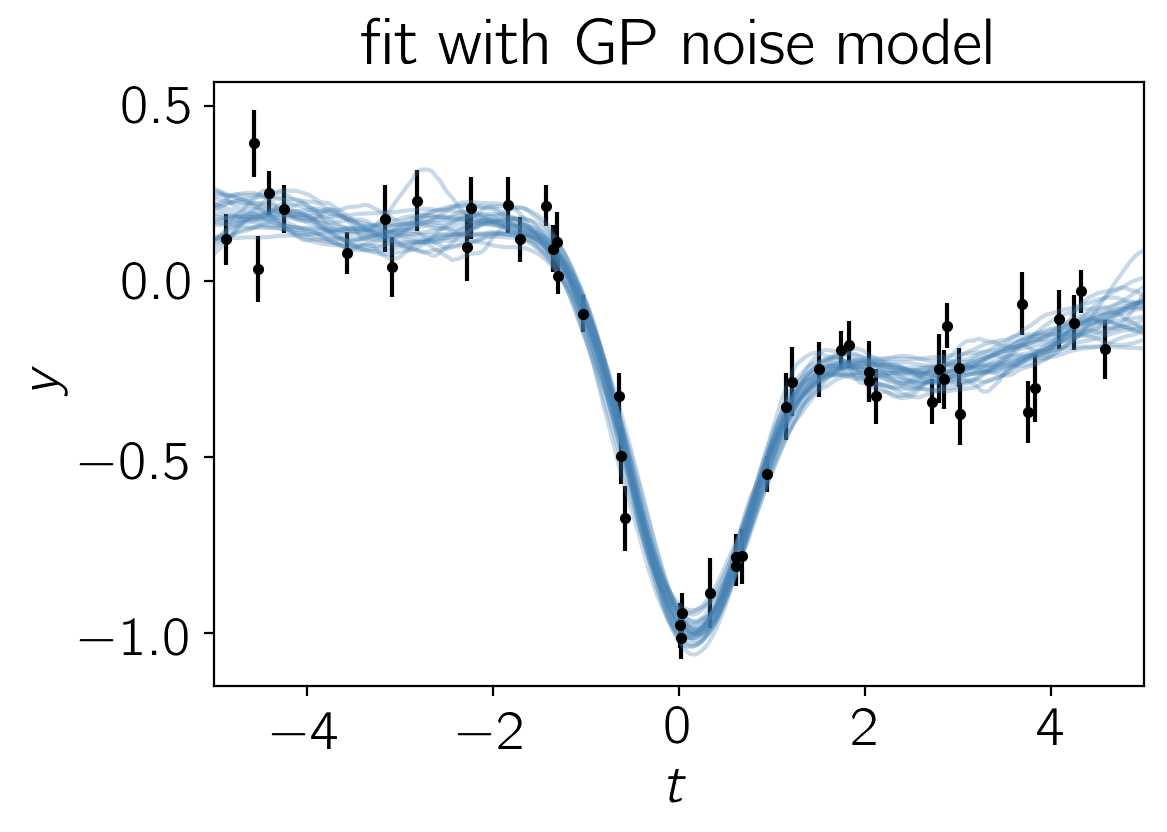
The plotting code for the results for this model is similar to the code in the previous section. First, we can plot the posterior samples on top of the data:
# Plot the data.
pl.errorbar(t, y, yerr=yerr, fmt=".k", capsize=0)
# The positions where the prediction should be computed.
x = np.linspace(-5, 5, 500)
# Plot 24 posterior samples.
samples = sampler.flatchain
for s in samples[np.random.randint(len(samples), size=24)]:
gp.set_parameter_vector(s)
mu = gp.sample_conditional(y, x)
pl.plot(x, mu, color="#4682b4", alpha=0.3)
pl.ylabel(r"$y$")
pl.xlabel(r"$t$")
pl.xlim(-5, 5)
pl.title("fit with GP noise model");
names = gp.get_parameter_names()
inds = np.array([names.index("mean:"+k) for k in tri_cols])
corner.corner(sampler.flatchain[:, inds], truths=tri_truths, labels=tri_labels);
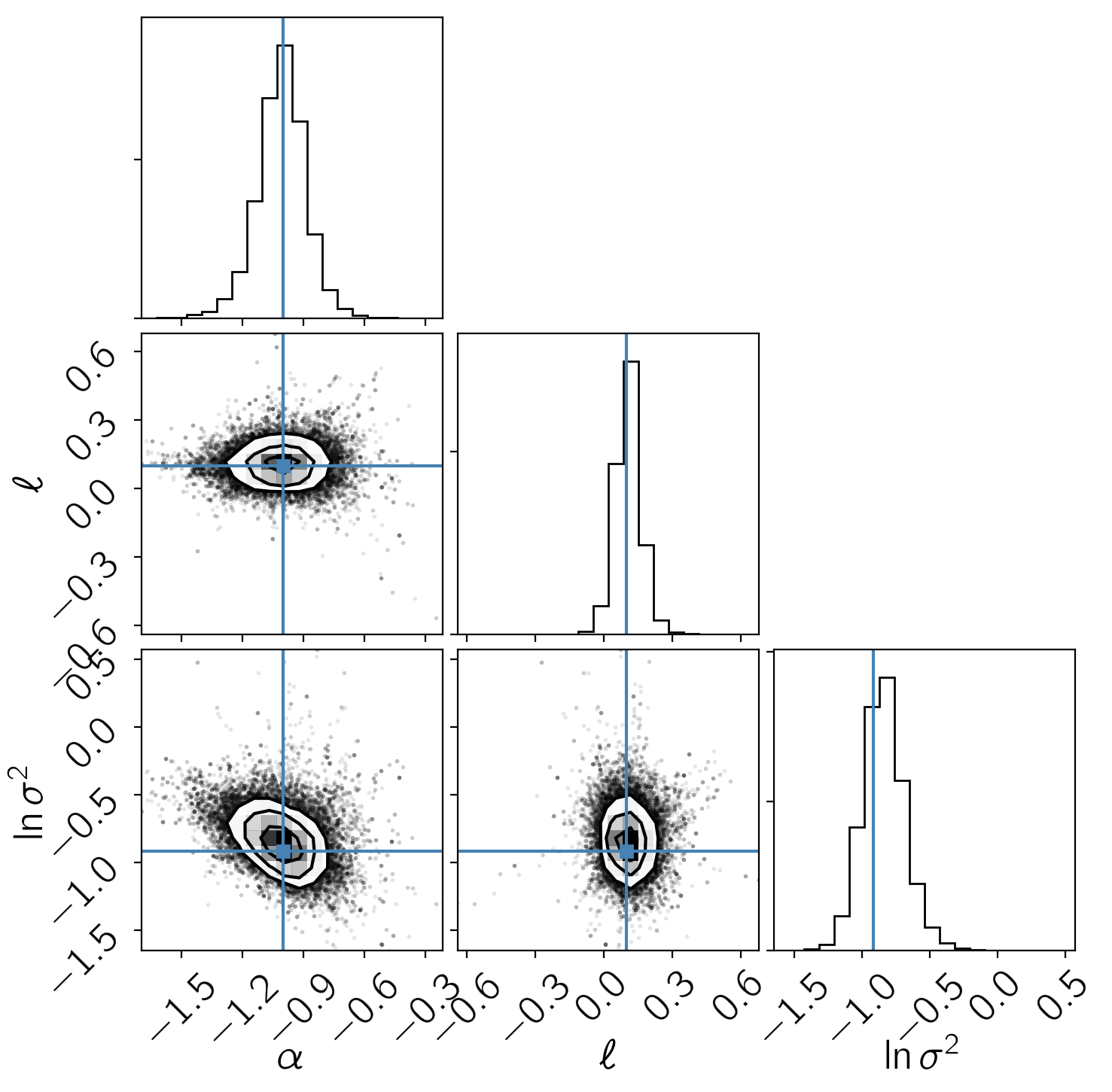
It is clear from this figure that the constraints obtained when modeling the noise are less precise (the error bars are larger) but more accurate (and honest).